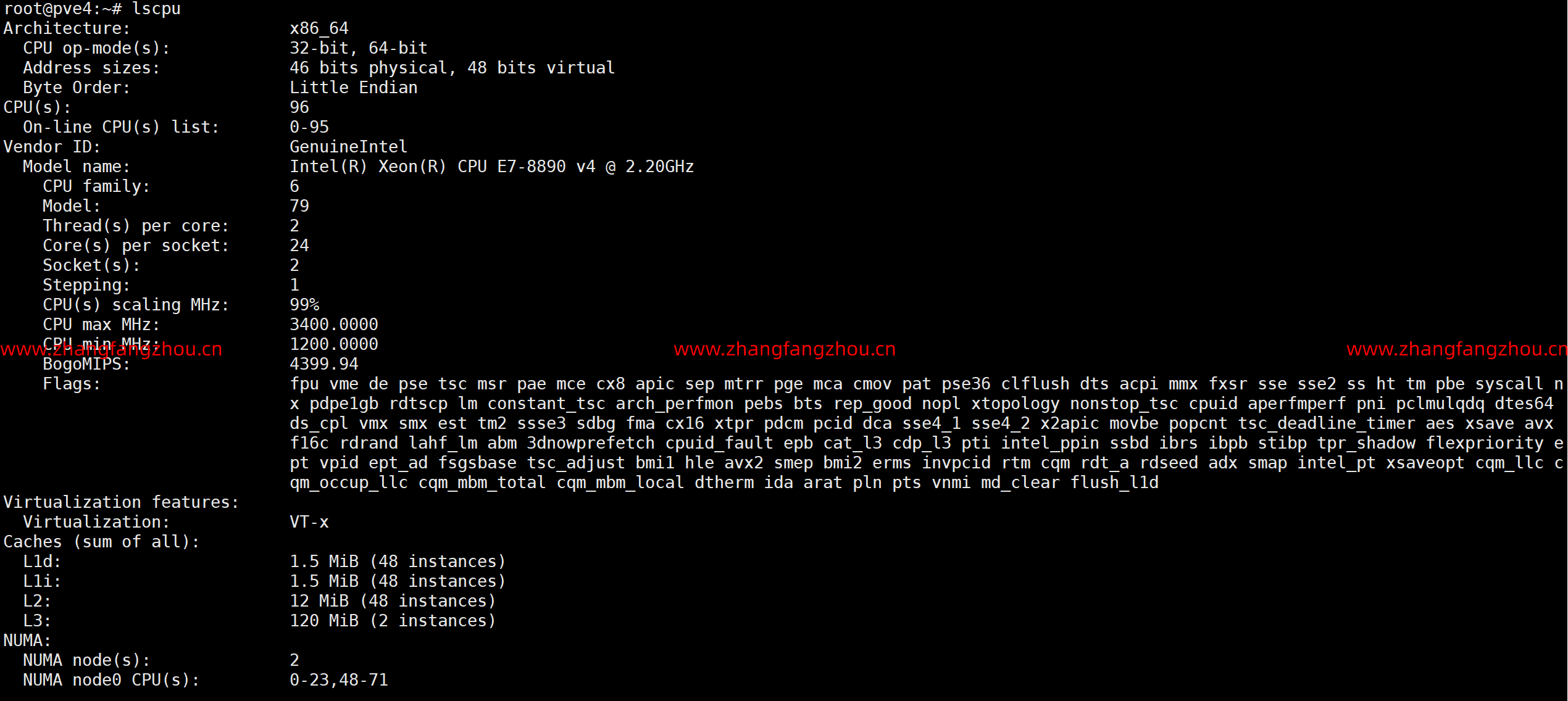
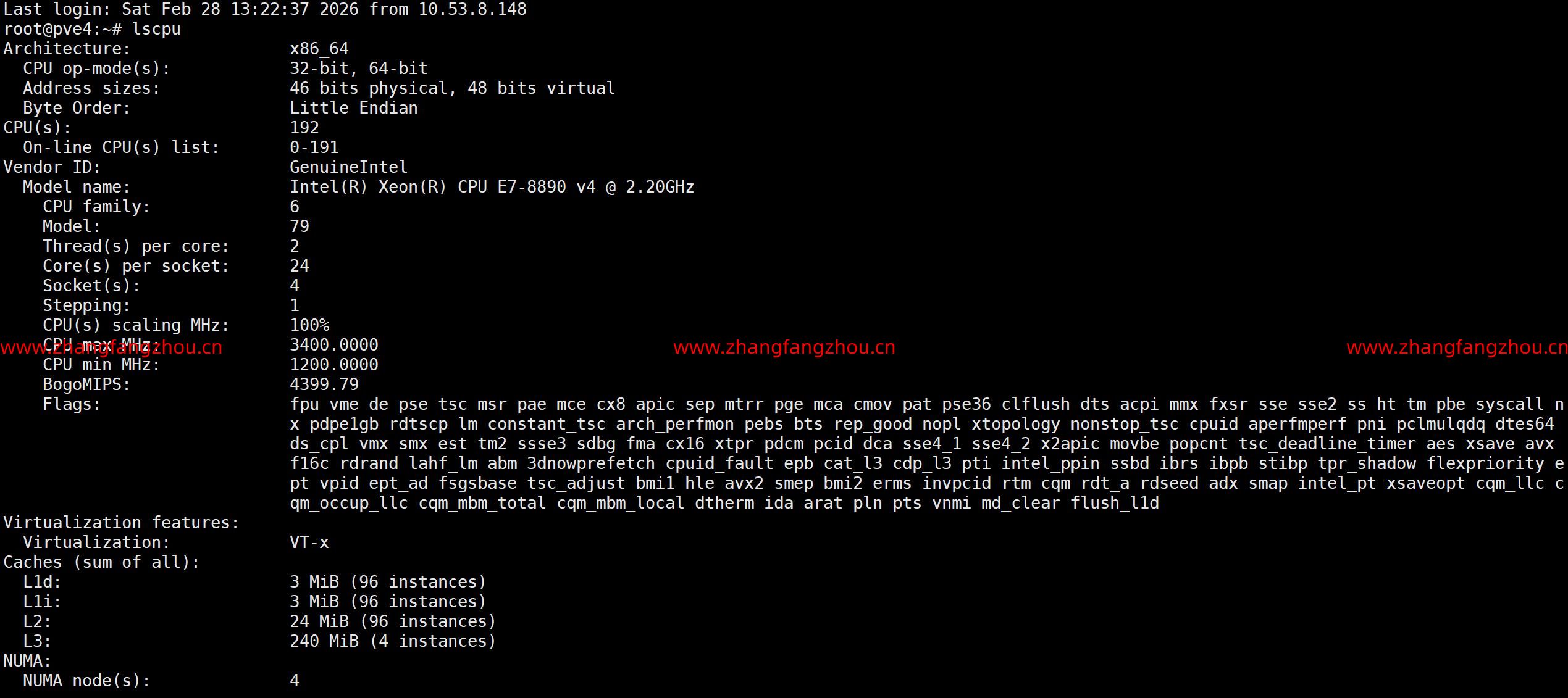
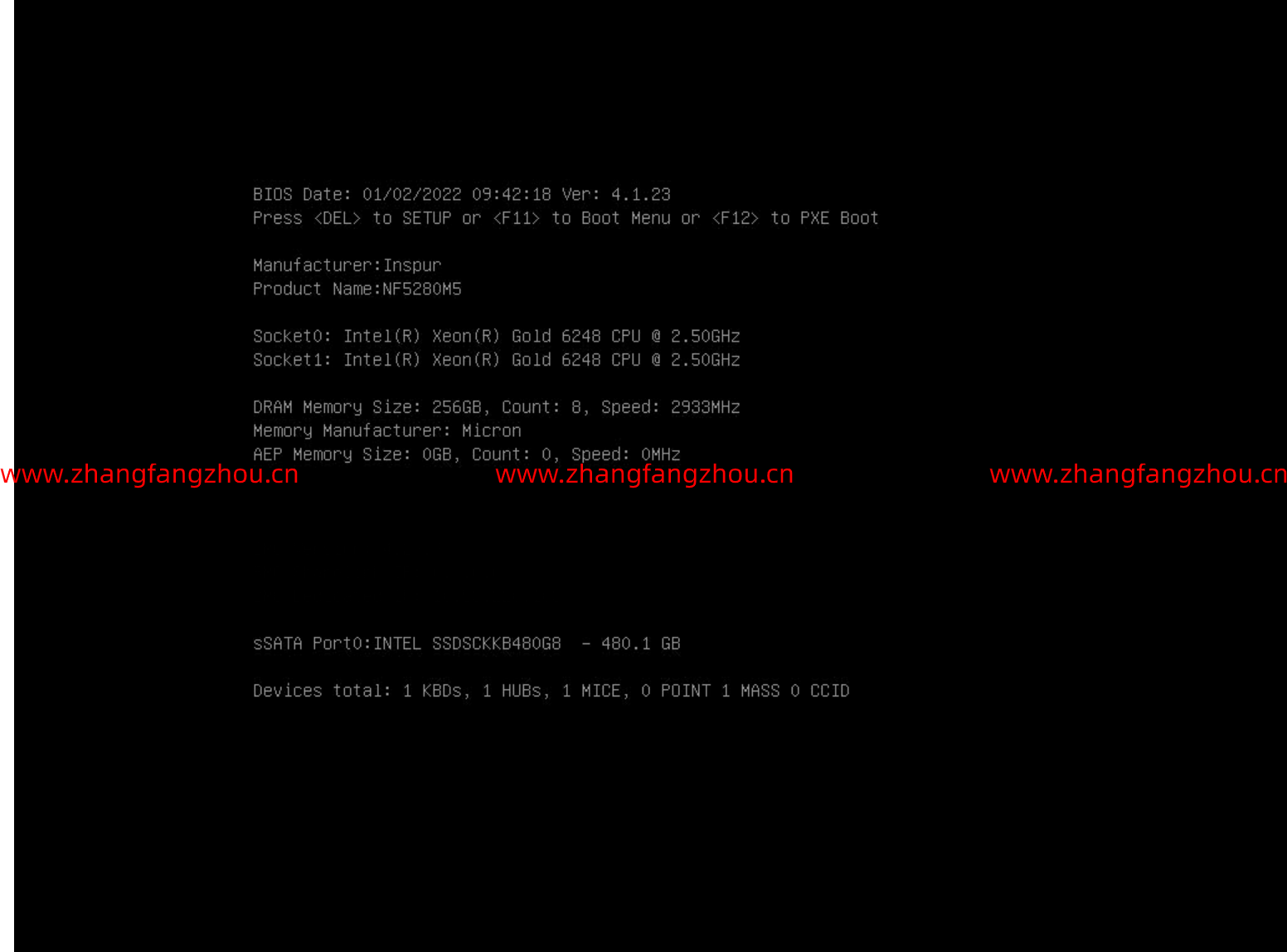
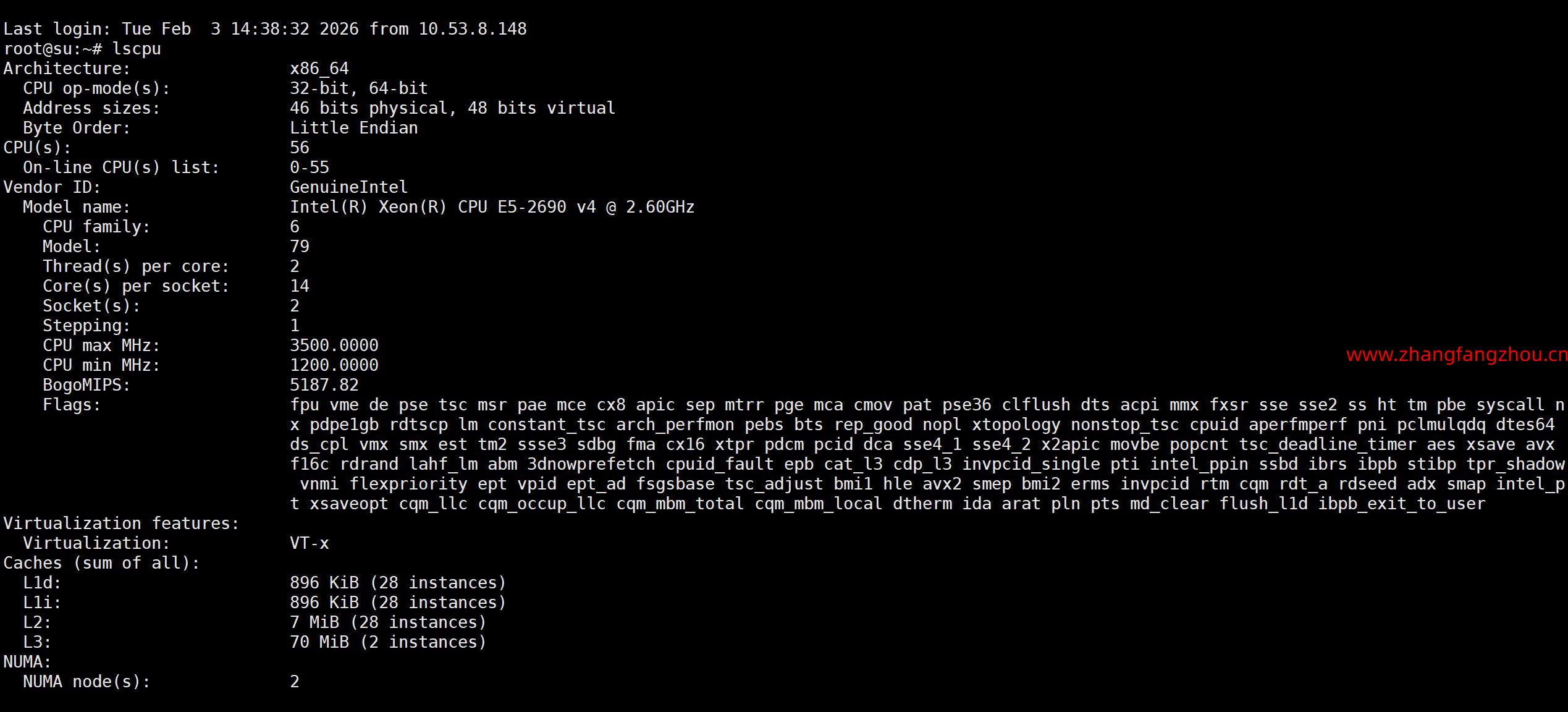
基于DHCP服务器使用 PXE 引导和 kickstart (UEFI) 自动安装 ESXi 7
基于UEFI的PXE安装 ESXi 7
PXE网络引导自动化安装 ESXi 7 详解
PXE+Kickstart 批量安装 ESXi 7
使用PXE 和TFTP 引导ESXi 安装ESXi 7 程序
1 基于DHCP服务器使用 PXE 引导和 kickstart (UEFI) 自动安装 ESXi 7 录制视频
2 浪潮NF5280M5服务器基于DHCP服务器使用 PXE 引导和 kickstart (UEFI) 自动安装 ESXi 7 录制视频

#CentOS 7 系统 安装dhcp服务器 、 tftp-server服务器 、 web服务器
yum install -y dhcp tftp-server httpd
1、配置DHCP服务器
守护进程 :/etc/sbin/dhcpd
脚本:/etc/init.d/dhcpd
端口:67(bootps) 服务端,68(bootpc) 客户端
配置文件:/etc/dhcp/dhcpd.conf
租约信息:/var/lib/dhcpd/dhcpd.leases
配置文件:cp /usr/share/doc/dhcp-4.2.5/dhcpd.conf.example /etc/dhcp/dhcpd.conf
修改DHCP监听特定端口 vi /etc/sysconfig/dhcpd
#编辑DHCP服务器配置文件
vi /etc/dhcp/dhcpd.conf
default-lease-time 600;
max-lease-time 7200;
log-facility local7;
subnet 10.53.220.0 netmask 255.255.255.0 {
range 10.53.220.41 10.53.220.49;
option domain-name-servers 10.1.0.1, 114.114.114.114; #DNS服务器IP地址
option routers 10.53.220.1; #网关地址
next-server 10.53.220.224; # 指定TFTP服务器地址
filename "/mboot.efi"; # 指定网络引导映像文件
}
#绑定IP地址
host zhangfangzhou { #zhangfangzhou 随意指定,但必须唯一
hardware ethernet 00:50:56:99:06:b7;
fixed-address 10.53.220.48;
}
#DHCP的服务设置开机启动、启动DHCP服务
systemctl enable dhcpd && systemctl start dhcpd
########防火墙设置
firewall-cmd --zone=public --add-port=67/udp --permanent
firewall-cmd --zone=public --add-port=68/udp --permanent
#重新载入配置
firewall-cmd --reload
firewall-cmd --list-all #查看防火墙规则,只显示/etc/firewalld/zones/public.xml中防火墙策略

2、配置 tftp 服务器
启用 tftp 服务
vi /etc/xinetd.d/tftp
# default: off
# description: The tftp server serves files using the trivial file transfer \
# protocol. The tftp protocol is often used to boot diskless \
# workstations, download configuration files to network-aware printers, \
# and to start the installation process for some operating systems.
service tftp
{
socket_type = dgram
protocol = udp
wait = yes
user = root
server = /usr/sbin/in.tftpd
server_args = -s /var/lib/tftpboot # TFTP服务器顶级目录
disable = no # 从yes修改为no
per_source = 11
cps = 100 2
flags = IPv4
}
#tftp的服务设置开机启动、启动tftp服务
systemctl enable tftp && systemctl start tftp
########防火墙设置
firewall-cmd --zone=public --add-port=69/tcp --permanent
firewall-cmd --zone=public --add-port=69/udp --permanent
#重新载入配置
firewall-cmd --reload
firewall-cmd --list-all #查看防火墙规则,只显示/etc/firewalld/zones/public.xml中防火墙策略

3、挂载ESXi 7 镜像
#创建文件夹,主要是下载ESXi 7和挂载ESXi 7使用
mkdir -p /var/lib/tftpboot/{iso,ESXi70u2}
wget -P /var/lib/tftpboot/iso http://10.53.123.144/ISO/ESXi/VMware-VMvisor-Installer-7.0U2a-17867351.x86_64.iso
cd /var/lib/tftpboot
mount /var/lib/tftpboot/iso/VMware-VMvisor-Installer-7.0U2a-17867351.x86_64.iso /var/lib/tftpboot/ESXi70u2 #重启后需要重新mount
#1、UEFI启动 ESXi 7
将上面DHCP服务器指定的启动镜像文件复制到指定目录下。上面的设置示例名为“mboot.efi”,因此将其复制为该名称。
cd /var/lib/tftpboot/
cp -p /var/lib/tftpboot/ESXi70u2/efi/boot/bootx64.efi /var/lib/tftpboot/mboot.efi
直接在 tftpboot 下复制名为 boot.cfg 的文件,该文件描述了引导设置。
cp -p /var/lib/tftpboot/ESXi70u2/efi/boot/boot.cfg /var/lib/tftpboot/boot.cfg
#2、传统BIOS启动 ESXi 7
如果要使用旧版 BIOS,则需要3.86版的 syslinux 软件包。从 https://www.kernel.org/pub/linux/utils/boot/syslinux/ 下载包
cd /tmp
wget https://mirrors.edge.kernel.org/pub/linux/utils/boot/syslinux/3.xx/syslinux-3.86.tar.gz
tar xvzf syslinux-3.86.tar.gz
cp -p syslinux-3.86/core/mboot.efi /var/lib/tftpboot/
#3、修改boot.cfg
删除 boot.cfg 中文件路径的“/”
sed -i 's|/||g' boot.cfg
4、检查boot.cfg
根据您的环境更改“标题”和“前缀”。为“title”使用一个描述性名称是个好主意,它是自动安装过程中显示的标题字符。“前缀prefix”指定存储 ESXi 安装程序的目录。在这种情况下,它将是“ESXi70u2”。
修改title和refix名称
prefix=ESXi70u2 (ESXi70u2就是上面ESXi ISO文件mount的文件夹)
# vi /var/lib/tftpboot/boot.cfg
bootstate=0
title=Loading ESXi installer www.zhangfangzhou.cn
timeout=5
prefix=ESXi70u2
kernel=b.b00
kernelopt=runweasel cdromBoot
modules=jumpstrt.gz --- useropts.gz --- features.gz --- k.b00 --- uc_intel.b00 --- uc_amd.b00 --- uc_hygon.b00 --- procfs.b00 --- vmx.v00 --- vim.v00 --- tpm.v00 --- sb.v00 --- s.v00 --- atlantic.v00 --- bnxtnet.v00 --- bnxtroce.v00 --- brcmfcoe.v00 --- brcmnvme.v00 --- elxiscsi.v00 --- elxnet.v00 --- i40enu.v00 --- iavmd.v00 --- icen.v00 --- igbn.v00 --- irdman.v00 --- iser.v00 --- ixgben.v00 --- lpfc.v00 --- lpnic.v00 --- lsi_mr3.v00 --- lsi_msgp.v00 --- lsi_msgp.v01 --- lsi_msgp.v02 --- mtip32xx.v00 --- ne1000.v00 --- nenic.v00 --- nfnic.v00 --- nhpsa.v00 --- nmlx4_co.v00 --- nmlx4_en.v00 --- nmlx4_rd.v00 --- nmlx5_co.v00 --- nmlx5_rd.v00 --- ntg3.v00 --- nvme_pci.v00 --- nvmerdma.v00 --- nvmxnet3.v00 --- nvmxnet3.v01 --- pvscsi.v00 --- qcnic.v00 --- qedentv.v00 --- qedrntv.v00 --- qfle3.v00 --- qfle3f.v00 --- qfle3i.v00 --- qflge.v00 --- rste.v00 --- sfvmk.v00 --- smartpqi.v00 --- vmkata.v00 --- vmkfcoe.v00 --- vmkusb.v00 --- vmw_ahci.v00 --- clusters.v00 --- crx.v00 --- elx_esx_.v00 --- btldr.v00 --- esx_dvfi.v00 --- esx_ui.v00 --- esxupdt.v00 --- tpmesxup.v00 --- weaselin.v00 --- loadesx.v00 --- lsuv2_hp.v00 --- lsuv2_in.v00 --- lsuv2_ls.v00 --- lsuv2_nv.v00 --- lsuv2_oe.v00 --- lsuv2_oe.v01 --- lsuv2_oe.v02 --- lsuv2_sm.v00 --- native_m.v00 --- qlnative.v00 --- vdfs.v00 --- vmware_e.v00 --- vsan.v00 --- vsanheal.v00 --- vsanmgmt.v00 --- tools.t00 --- xorg.v00 --- gc.v00 --- imgdb.tgz --- basemisc.tgz --- resvibs.tgz --- imgpayld.tgz
build=7.0.2-0.0.17867351
updated=0
到这一步可以实现通过PXE网络安装ESXi
5、配置web 服务器
#默认网站目录/var/www/html
systemctl enable httpd && systemctl start httpd
########防火墙设置
firewall-cmd --zone=public --add-port=80/tcp --permanent
firewall-cmd --zone=public --add-port=443/tcp --permanent
#重新载入配置
firewall-cmd --reload
firewall-cmd --list-all #查看防火墙规则,只显示/etc/firewalld/zones/public.xml中防火墙策略
6、配置 ESXi 7 的 kickstart
示例 kickstart 文件存储在 ESXi 的 /etc/vmware/weasel/ks.cfg 中。将此复制到 http 服务器上的 /var/www/html
#示例 1 kickstart 文件,给ESXi 7 配置 静态IP地址
vi /var/www/html/ks.cfg
#####################
# Accept the VMware End User License Agreement
vmaccepteula
# Set the root password for the DCUI and Tech Support Mode
rootpw P@ssw0rd
# The install media is in the CD-ROM drive
install --firstdisk --overwritevmfs
# Set the network on the first network adapter
network --bootproto=static --device=vmnic0 --ip=10.53.220.199 --netmask=255.255.255.0 --vlanid=0 --gateway=10.53.220.1 --hostname=10.53.220.199 --nameserver=10.1.0.1
#vmserialnum
vmserialnum --esx=5U4TK-DML1M-M8550-XK1QP-1A052
# reboot after install
reboot
# run the following command only on the firstboot
%firstboot --interpreter=busybox
sleep 10
# enable & start remote ESXi Shell (SSH)
vim-cmd hostsvc/enable_ssh
vim-cmd hostsvc/start_ssh
sleep 1
# enable & start ESXi Shell (TSM)
vim-cmd hostsvc/enable_esx_shell
vim-cmd hostsvc/start_esx_shell
sleep 1
# enable High Performance
esxcli system settings advanced set --option=/Power/CpuPolicy --string-value="High Performance"
sleep 1
#Disable ipv6
esxcli network ip set --ipv6-enabled=0
sleep 1
#不加入体验
esxcli system settings advanced set -o /UserVars/HostClientCEIPOptIn -i 2
sleep 1
#enable ntp
/bin/esxcli system ntp set --server=ntp.aliyun.com
sleep 1
/bin/chkconfig ntpd on
sleep 1
#Disable ShellWarning
esxcli system settings advanced set -o /UserVars/SuppressShellWarning -i 1
sleep 1
cat << EOF > /etc/ssh/keys-root/authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAgEA6PP8/RDdYIqUq6DE3zj9Qs8AF3uzfYH5lYrB+mMxxfI8kq2NIzQlsW1KDaH/fWYTkkK120lPUu97lWic9Li3Z3iFR6Nh4q6PVTfBNt4xOx754Ipqtpefk+9sLZAYEPK8pnRP0QZv7CtDFv842tfUYIrVNnecRQTFfNtnGDcXnO1u2RE1kq6Tr5N3595PbPLDKczjOFnS+jy0MeKKHPJcZfYz7TUTSzTwTHYbPRRaQ8/0eihUwzpAmXRo9NYNle26qp6+SlRsjGSBcUr0rh0wSe6r/C2btnpOUd//aFvcl8plhyb++nivlhB71v+6I0UcPoSXOIVs/1QuHEMbv7Ircjb2emqHtZDpk8KSYhgV0ZdbAq9XOcux76eok//xtjbleKPAcDMY/KotIEh7QX4NLQxSJOm5gCLkn5kbrHfVx6nWlGzVVds1sDlcnSAWul5lFiI5ZkArXFKcnm+aCnStPpx5SSCpZpMUdZvt8ZA7vLx3xjMDFwv5HTuTFwB9mlZrdfqp5USC2mWC3eAAPE7GxDSfJv9epteIYywIP9NVT3Z4ng9z6jrcFfA4GFlfLrk8J71cnxZ/AWZXXUwp3ooE/Cp3jc473VpK7FZwjQ7Xz9PD8WQgMOO4xnGQhPWlxhRuoTYyQVa0xOBO9gh9Cuc6zq5FQgYQEcSB+/FBJ/YNDIc= www.zhangfangzhou.cn
EOF
sleep 1
date > /finished.stamp
# Restart a last time
reboot
#示例 2 kickstart 文件,ESXi 7 通过 DHCP 服务器获得IP地址
vi /var/www/html/ks.cfg
# Accept the VMware End User License Agreement
vmaccepteula
# Set the root password for the DCUI and Tech Support Mode
rootpw P@ssw0rd
# The install media is in the CD-ROM drive
install --firstdisk --overwritevmfs
# Set the network on the first network adapter
network --bootproto=dhcp
#vmserialnum
vmserialnum --esx=5U4TK-DML1M-M8550-XK1QP-1A052
# reboot after install
reboot
# run the following command only on the firstboot
%firstboot --interpreter=busybox
sleep 10
# enable & start remote ESXi Shell (SSH)
vim-cmd hostsvc/enable_ssh
vim-cmd hostsvc/start_ssh
sleep 1
# enable & start ESXi Shell (TSM)
vim-cmd hostsvc/enable_esx_shell
vim-cmd hostsvc/start_esx_shell
sleep 1
# enable High Performance
esxcli system settings advanced set --option=/Power/CpuPolicy --string-value="High Performance"
sleep 1
#Disable ipv6
esxcli network ip set --ipv6-enabled=0
sleep 1
#不加入体验
esxcli system settings advanced set -o /UserVars/HostClientCEIPOptIn -i 2
sleep 1
#enable ntp
/bin/esxcli system ntp set --server=ntp.aliyun.com
sleep 1
/bin/chkconfig ntpd on
sleep 1
#Disable ShellWarning
esxcli system settings advanced set -o /UserVars/SuppressShellWarning -i 1
sleep 1
cat << EOF > /etc/ssh/keys-root/authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAgEA6PP8/RDdYIqUq6DE3zj9Qs8AF3uzfYH5lYrB+mMxxfI8kq2NIzQlsW1KDaH/fWYTkkK120lPUu97lWic9Li3Z3iFR6Nh4q6PVTfBNt4xOx754Ipqtpefk+9sLZAYEPK8pnRP0QZv7CtDFv842tfUYIrVNnecRQTFfNtnGDcXnO1u2RE1kq6Tr5N3595PbPLDKczjOFnS+jy0MeKKHPJcZfYz7TUTSzTwTHYbPRRaQ8/0eihUwzpAmXRo9NYNle26qp6+SlRsjGSBcUr0rh0wSe6r/C2btnpOUd//aFvcl8plhyb++nivlhB71v+6I0UcPoSXOIVs/1QuHEMbv7Ircjb2emqHtZDpk8KSYhgV0ZdbAq9XOcux76eok//xtjbleKPAcDMY/KotIEh7QX4NLQxSJOm5gCLkn5kbrHfVx6nWlGzVVds1sDlcnSAWul5lFiI5ZkArXFKcnm+aCnStPpx5SSCpZpMUdZvt8ZA7vLx3xjMDFwv5HTuTFwB9mlZrdfqp5USC2mWC3eAAPE7GxDSfJv9epteIYywIP9NVT3Z4ng9z6jrcFfA4GFlfLrk8J71cnxZ/AWZXXUwp3ooE/Cp3jc473VpK7FZwjQ7Xz9PD8WQgMOO4xnGQhPWlxhRuoTYyQVa0xOBO9gh9Cuc6zq5FQgYQEcSB+/FBJ/YNDIc= www.zhangfangzhou.cn
EOF
sleep 1
date > /finished.stamp
# Restart a last time
reboot

7、最终boot.cfg配置文件
# vi /var/lib/tftpboot/boot.cfg
bootstate=0
title=Loading ESXi installer www.zhangfangzhou.cn
timeout=5
prefix=ESXi70u2
kernel=b.b00
kernelopt=ks=http://10.53.220.224/ks.cfg
modules=jumpstrt.gz --- useropts.gz --- features.gz --- k.b00 --- uc_intel.b00 --- uc_amd.b00 --- uc_hygon.b00 --- procfs.b00 --- vmx.v00 --- vim.v00 --- tpm.v00 --- sb.v00 --- s.v00 --- atlantic.v00 --- bnxtnet.v00 --- bnxtroce.v00 --- brcmfcoe.v00 --- brcmnvme.v00 --- elxiscsi.v00 --- elxnet.v00 --- i40enu.v00 --- iavmd.v00 --- icen.v00 --- igbn.v00 --- irdman.v00 --- iser.v00 --- ixgben.v00 --- lpfc.v00 --- lpnic.v00 --- lsi_mr3.v00 --- lsi_msgp.v00 --- lsi_msgp.v01 --- lsi_msgp.v02 --- mtip32xx.v00 --- ne1000.v00 --- nenic.v00 --- nfnic.v00 --- nhpsa.v00 --- nmlx4_co.v00 --- nmlx4_en.v00 --- nmlx4_rd.v00 --- nmlx5_co.v00 --- nmlx5_rd.v00 --- ntg3.v00 --- nvme_pci.v00 --- nvmerdma.v00 --- nvmxnet3.v00 --- nvmxnet3.v01 --- pvscsi.v00 --- qcnic.v00 --- qedentv.v00 --- qedrntv.v00 --- qfle3.v00 --- qfle3f.v00 --- qfle3i.v00 --- qflge.v00 --- rste.v00 --- sfvmk.v00 --- smartpqi.v00 --- vmkata.v00 --- vmkfcoe.v00 --- vmkusb.v00 --- vmw_ahci.v00 --- clusters.v00 --- crx.v00 --- elx_esx_.v00 --- btldr.v00 --- esx_dvfi.v00 --- esx_ui.v00 --- esxupdt.v00 --- tpmesxup.v00 --- weaselin.v00 --- loadesx.v00 --- lsuv2_hp.v00 --- lsuv2_in.v00 --- lsuv2_ls.v00 --- lsuv2_nv.v00 --- lsuv2_oe.v00 --- lsuv2_oe.v01 --- lsuv2_oe.v02 --- lsuv2_sm.v00 --- native_m.v00 --- qlnative.v00 --- vdfs.v00 --- vmware_e.v00 --- vsan.v00 --- vsanheal.v00 --- vsanmgmt.v00 --- tools.t00 --- xorg.v00 --- gc.v00 --- imgdb.tgz --- basemisc.tgz --- resvibs.tgz --- imgpayld.tgz
build=7.0.2-0.0.17867351
updated=0
 到这里可以基于DHCP实现通过PXE自动安装 ESXi 7、自动设置系统密码、自动接受许可、自动添加产品密钥、自动启用SSH服务、自动启用shell服务、电源模式自动设置为高性能、禁用IPV6、不参加(CEIP)客户体验改善计划、自动配置NTP、自动添加私钥。
到这里可以基于DHCP实现通过PXE自动安装 ESXi 7、自动设置系统密码、自动接受许可、自动添加产品密钥、自动启用SSH服务、自动启用shell服务、电源模式自动设置为高性能、禁用IPV6、不参加(CEIP)客户体验改善计划、自动配置NTP、自动添加私钥。
https://www.zhangfangzhou.cn/pxe-kickstart-install-uefi-esxi-7.html