如何在Ubuntu 22.04上安装GeForce RTX 4090驱动程序和CUDA
How to Install GeForce RTX 4090 Drivers and CUDA on Ubuntu 22.04
如何在Ubuntu 22.04上安装GeForce RTX 2080TI驱动程序和CUD
How to Install GeForce RTX 2080 TI Drivers and CUDA on Ubuntu 22.04
1. 打开终端并更新
使用sudo更新apt软件包列表并使用sudo升级apt软件包
sudo apt update && sudo apt upgrade -y sudo apt install build-essential dkms linux-headers-$(uname -r) -y
2. 确定可用驱动
使用sudo命令列出ubuntu驱动程序列表
sudo ubuntu-drivers list ...... nvidia-driver-565, (kernel modules provided by nvidia-dkms-565) nvidia-driver-535, (kernel modules provided by linux-modules-nvidia-535-generic) nvidia-driver-575, (kernel modules provided by nvidia-dkms-575) nvidia-driver-555-open, (kernel modules provided by nvidia-dkms-555-open) nvidia-driver-575-open, (kernel modules provided by nvidia-dkms-575-open) nvidia-driver-570-server, (kernel modules provided by linux-modules-nvidia-570-server-generic) nvidia-driver-555, (kernel modules provided by nvidia-dkms-555) nvidia-driver-535-server-open, (kernel modules provided by linux-modules-nvidia-535-server-open-generic) nvidia-driver-560, (kernel modules provided by nvidia-dkms-560) nvidia-driver-570-server-open, (kernel modules provided by linux-modules-nvidia-570-server-open-generic) nvidia-driver-570-open, (kernel modules provided by linux-modules-nvidia-570-open-generic) nvidia-driver-535-server, (kernel modules provided by linux-modules-nvidia-535-server-generic) nvidia-driver-560-open, (kernel modules provided by nvidia-dkms-560-open) nvidia-driver-565-open, (kernel modules provided by nvidia-dkms-565-open) nvidia-driver-550, (kernel modules provided by linux-modules-nvidia-550-generic) nvidia-driver-550-open, (kernel modules provided by linux-modules-nvidia-550-open-generic) nvidia-driver-570, (kernel modules provided by linux-modules-nvidia-570-generic) nvidia-driver-535-open, (kernel modules provided by linux-modules-nvidia-535-open-generic) open-vm-tools-desktop
3.禁用 Nouveau 驱动:创建配置文件并更新,重启系统
sudo cat <<EOF | sudo tee /etc/modprobe.d/blacklist-nvidia.conf blacklist nouveau blacklist nvidia blacklist nvidiafb blacklist rivafb EOF sudo update-initramfs -u sudo reboot
4.安装驱动
sudo apt install nvidia-driver-570 -y #sudo apt install nvidia-driver-580 -y
5.验证GeForce RTX 4090驱动是否正常加载
root@lenovo-ThinkStation-PX:~# nvidia-smi
Fri Jul 18 17:13:35 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.169 Driver Version: 570.169 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:2A:00.0 Off | Off |
| 32% 42C P8 34W / 450W | 87MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA GeForce RTX 4090 Off | 00000000:3D:00.0 Off | Off |
| 30% 34C P8 16W / 450W | 15MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 2 NVIDIA GeForce RTX 4090 Off | 00000000:BD:00.0 Off | Off |
| 32% 32C P8 6W / 450W | 15MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 3 NVIDIA GeForce RTX 4090 Off | 00000000:E1:00.0 Off | Off |
| 32% 33C P8 15W / 450W | 15MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 2453 G /usr/lib/xorg/Xorg 46MiB |
| 0 N/A N/A 2564 G /usr/bin/gnome-shell 13MiB |
| 1 N/A N/A 2453 G /usr/lib/xorg/Xorg 4MiB |
| 2 N/A N/A 2453 G /usr/lib/xorg/Xorg 4MiB |
| 3 N/A N/A 2453 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------------------+
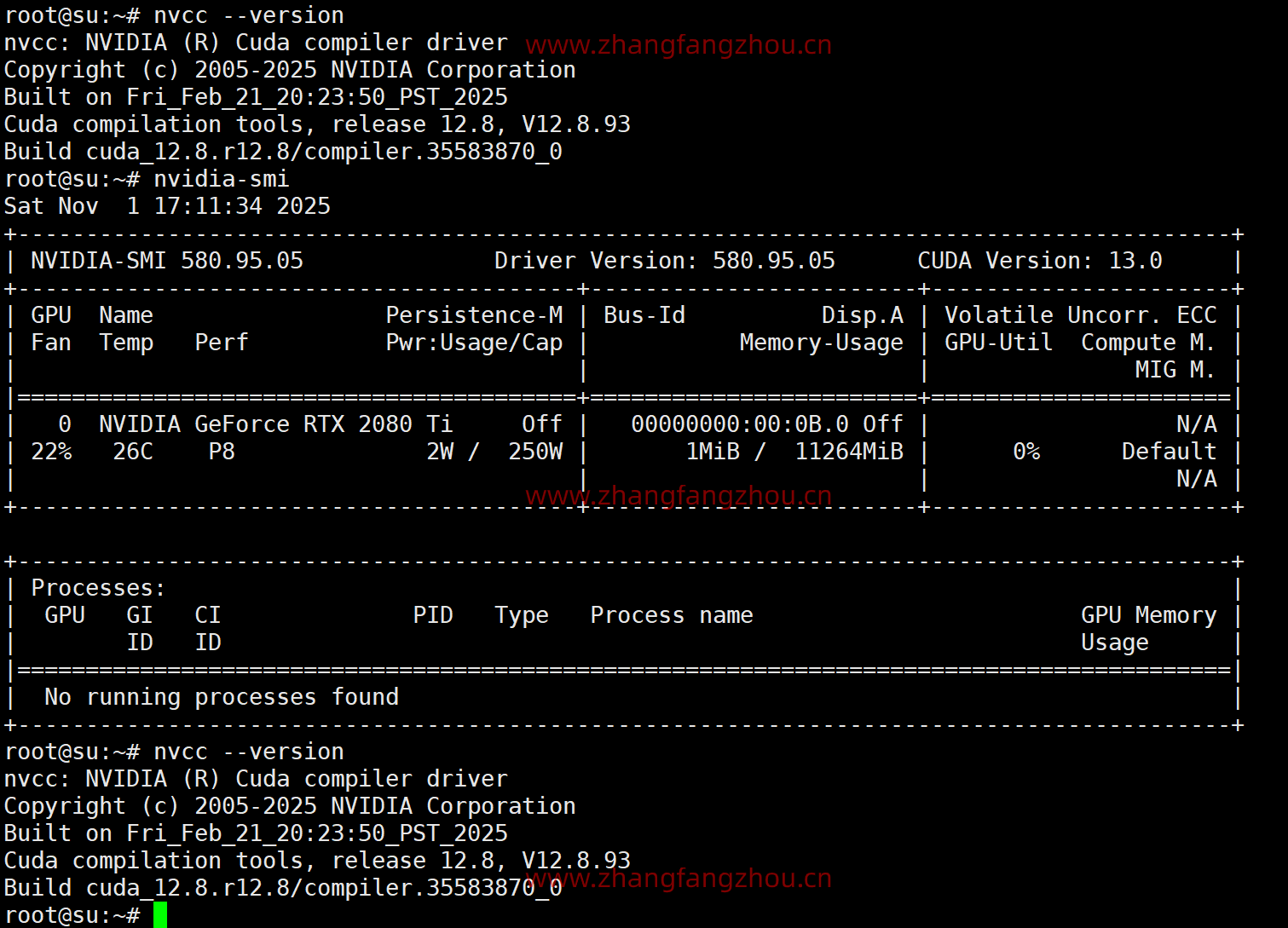
验证GeForce RTX 2080 TI驱动是否正常加载
root@su:~# nvidia-smi Sat Nov 1 12:04:44 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 580.95.05 Driver Version: 580.95.05 CUDA Version: 13.0 | +-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 2080 Ti Off | 00000000:00:0B.0 Off | N/A | | 16% 35C P0 86W / 250W | 1MiB / 11264MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
6.安装 CUDA
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-8
用 nvcc --version 确认cuda的版本,如果显示Command nvcc not found,则编辑~/.bashrc
vim ~/.bashrc
export PATH=/usr/local/cuda-12.8/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
#更新变量
source ~/.bashrc
root@su:~# nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Fri_Feb_21_20:23:50_PST_2025
Cuda compilation tools, release 12.8, V12.8.93
Build cuda_12.8.r12.8/compiler.35583870_0
7.锁定驱动版本防止升级冲突
sudo apt-mark hold nvidia-driver-570 sudo apt-mark hold cuda-toolkit-12-8
GeForce RTX 4090

GeForce RTX 2080TI